
MIST (Molecular Insight SMILES Transformer)
A significant step towards accelerating materials discovery, design, and optimization using foundation models.
Chemical space is astronomically large and profoundly heterogeneous, spanning simple organics, inorganic salts, complex organometallics, and their mixtures. Traditional discovery workflows such as wet-lab screening and first-principles simulation probe only a small sliver of this space. Recent progress in foundation models suggests a different path: learn general, transferable representations from vast unlabeled molecular corpora rather than rely on scarce labeled data. MIST is built for this goal: a single molecular foundation model that resolves isotopic, stereochemical, structural, and electronic nuances, then transfers across tasks and domains, from energy materials to olfaction. By unifying breadth with scientific fidelity, MIST turns chemical space from an intractable search into a navigable landscape for discovery.

Most molecular foundation models use atom-wise tokenization, treating all ``bracketed atoms’’ as a single irreducible token. Bracketed atoms represent any atom outside the organic subset or atoms with an explicit nuclear, geometric, or electronic aspect. Treating each fully specified bracketed atom as a single token would require an astronomically large vocabulary; in practice, small vocabularies create coverage gaps. SMIRK addresses this by further decomposing bracketed atoms in chemically meaningful glyphs. This yields a tokenizer with complete coverage of the OpenSMILES specification, preserving isotopic and stereochemical information, avoiding information lossy due to out-of-vocabulary tokens, and producing interpretable embeddings for attributes that matter to downstream tasks.

The core advantage of a foundation model is that it can be adapted to a wide range of downstream tasks given a small number of labelled examples. We demonstrate the MIST models’ efficacy as scientific foundation models by fine-tuning variants of MIST to predict over 400 properties — including quantum mechanical, thermodynamic, biochemical, and psychophysical properties — from a molecule’s SMILES representation. The MIST encoders are fine-tuned on labelled datasets as small as 200 examples. The encoders are fine-tuned on single molecule property prediction (classification and regression) tasks by attaching a small two-layer MLP. They are fine-tuned on mixture property prediction tasks using a physics-informed task network architecture. These fine-tuned models unlock problem-solving capabilities across vast regions of chemical space at multiple scales, from single-molecule electrolyte solvents and odorants to large chiral organometallic structures and complex multi-component mixtures.
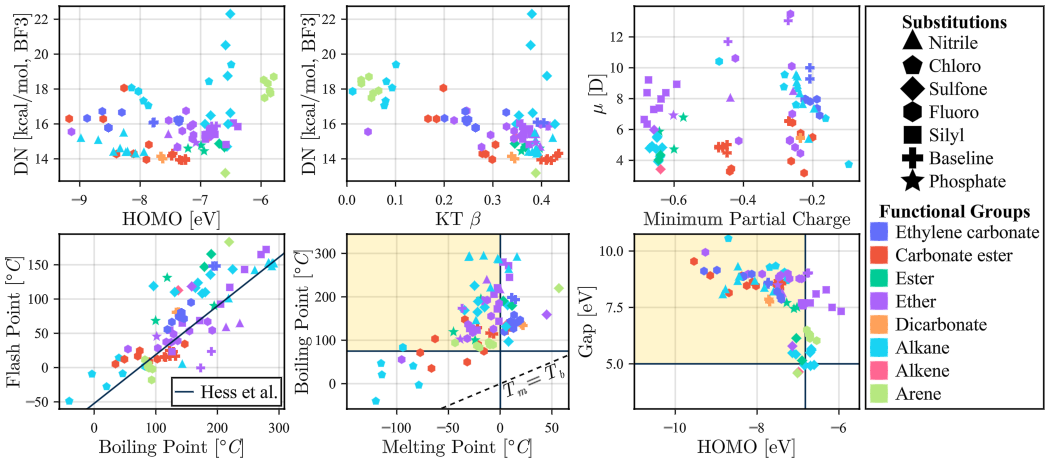
The promise of scientific foundation models like MIST goes beyond raw predictive accuracy. For exploration, scientists need representations that surface interpretable, concept-aligned features —– axes in the embedding space that correspond to recognizable scientific quantities or relationships and that can be read and steered to generate hypotheses or diagnose failure modes.
In language and vision, mechanistic interpretability has revealed feature vectors that align with meaningful concepts across tasks and modalities; comparable, systematic efforts for scientific models have been limited. Prior chemistry work has mostly inspected attention maps and low-dimensional projections as qualitative probes of internal behavior. We took a systematic approach to uncover concept-aligned directions across all layers of MIST. Using lightweight linear readouts and controlled perturbations, we identify axes tied to chemically meaningful ideas, such as drug-likeness attributes, aromaticity, polycyclic aromatic hydrocarbon subclasses and isotopic stability that emerge during self-supervised pretraining and persist under fine-tuning.
By turning latent structure into operational knobs —– readable directions that can be scored, visualized, or perturbed MIST enables hypothesis generation. In this role, MIST functions not merely as a high-accuracy predictor, but as a practical instrument for discovery and systematic exploration across chemical space.
